 您好,歡迎來到易龍商務網!
您好,歡迎來到易龍商務網!
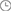 發布時間:2021-10-26 08:44
發布時間:2021-10-26 08:44
【廣告】








BlueSky高性能時序數據庫分片方法:
哈希分片: 均衡性較好,但集群不易擴展執行哈希:均衡性好,集群擴展易,但實現復雜范圍劃分:復雜度在于合并和分裂,全局有序分片設計
分片的會直接影響到寫入的性能,結合時序數據庫的特點,根據 metric tags 分片是比較好的方式,查詢大都是按照一個時間范圍進行的,這樣形同的 metric tags 數據會被分配到一臺機器上連續存放,順序的磁盤讀取是很快的。
在時間范圍很長的情況下,可以根據時間訪問再進行分段,分別存儲到不同的機器上,這樣大范圍的數據就可以支持并發查詢,優化查詢速度。
如下圖,行和第三行都是同樣的tag(sensor=95D8-7913;city=上海),所以分配到同樣的分片,而第五行雖然也是同樣的tag,但是根據時間范圍再分段,被分到了不同的分片。第二、四、六行屬于同樣的tag(sensor=F3CC-20F3;city=北京)也是一樣的道理。

BlueSky時間序列化數據庫如何聯合索引查詢?
所以給定查詢過濾條件 age=18 的過程就是先從 term index 找到 18 在 term dictionary 的大概位置,然后再從 term dictionary 里地找到 18 這個 term,然后得到一個 ting list 或者一個指向 ting list 位置的指針。然后再查詢 gender= 女 的過程也是類似的。得出 age=18 AND gender= 女 就是把兩個 ting list 做一個“與”的合并。
這個理論上的“與”合并的操作可不容易。對于 mysql 來說,如果你給 age 和 gender 兩個字段都建立了索引,查詢的時候只會選擇其中 selective 的來用,然后另外一個條件是在遍歷行的過程中在內存中計算之后過濾掉。那么要如何才能聯合使用兩個索引呢?有兩種辦法:使用 skip list 數據結構。同時遍歷 gender 和 age 的 ting list,互相 skip;使用 bitset 數據結構,對 gender 和 age 兩個 filter 分別求出 bitset,對兩個 bitset 做 AN 操作。
BlueSky高性能時序數據庫
非關系型數據庫會超過關系型數據庫,NoSQL會超過SQL。因為從社會構建的方式、交付的語言表述體系、視頻采集的方式、工業生產IoT時序性數據大量產生等多個角度看,大部分新生成的數據都將是非關系型數據。而據IDC預測,到2023年,產生的非關系型數據的量會超過關系型數據。

BlueSky時序數據庫怎么分
關系型數據庫本身比較容易成為系統瓶頸,單機存儲容量、連接數、處理能力都有限。當單表的數據量達到1000W或100G以后,由于查詢維度較多,即使添加從庫、優化索引,做很多操作時性能仍下降嚴重。此時就要考慮對其進行切分了,切分的目的就在于減少數據庫的負擔,縮短查詢時間。
數據庫分布式內容無非就是數據切分(Sharding),以及切分后對數據的定位、整合。數據切分就是將數據分散存儲到多個數據庫中,使得單一數據庫中的數據量變小,通過擴充主機的數量緩解單一數據庫的性能問題,從而達到提升數據庫操作性能的目的。
數據切分根據其切分類型,可以分為兩種方式:垂直(縱向)切分和水平(橫向)切分

